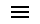

索引和目录的区别是什么(项目索引和目录的区别)
索引和目录的区别是什么(项目索引和目录的区别)
索引是什么?
数据库索引,是数据库管理系统(DBMS)中一个排序的数据结构,它可以对数据库表中一列或多列的值进行排序,以协助更加快速的访问数据库表中特定的数据。通俗的说,我们可以把数据库索引比做是一本书前面的目录,它能加快数据库的查询速度。
为什么需要索引?
思考:如何在一个图书馆中找到一本书?
设想一下,假如在图书馆中没有其他辅助手段,只能一条道走到黑,一本书一本书的找,经过3个小时的连续查找,终于找到了你需要看的那本书,但此时天都黑了。为了避免这样的事情,每个图书馆才都配备了一套图书馆管理系统,大家要找书籍的话,先在系统上查找到书籍所在的房屋编号、图书架编号还有书在图书架几层的那个方位,然后就可以直接大摇大摆的去取书了,就可以很快速的找到我们所需要的书籍。索引就是这个原理,它可以帮助我们快速的检索数据。
一般的应用系统对数据库的操作,遇到最多、最容易出问题是一些复杂的查询操作,当数据库中数据量很大时,查找数据就会变得很慢,这样就很影响整个应用系统的效率,我们就可以使用索引来提高数据库的查询效率。
B-Tree和B+Tree
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构, 我在这里分别讲一下:
B-Tree
即B树,注意(不是B减树),B树是一种多路搜索树。使用B-Tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。
B-Tree有如下一些特征:
定义任意非叶子结点最多只有M个子节点,且M>2。根结点的儿子数为[2, M]。除根结点以外的非叶子结点的儿子数为[M/2, M], 向上取整 。
每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)。非叶子结点的关键字个数=指向儿子的指针个数-1。非叶子结点的关键字:K[1], K[2], …, K[M-1],且K[i] <= K[i+1]。
非叶子结点的指针:P[1], P[2], …,P[M](其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树)。所有叶子结点位于同一层。
有关b树的一些特性:
关键字集合分布在整颗树的所有结点之中;任何一个关键字出现且只出现在一个结点中;搜索有可能在非叶子结点结束;其搜索性能等价于在关键字全集内做一次二分查找。
B树的搜索:从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复执行这个操作,直到所对应的节点指针为空,或者已经是是叶子结点。
例如下面一个B树,那么查找元素43的过程如下:
根据根节点指针找到18、37所在节点,把此节点读入内存,进行第一次磁盘IO,此时发现43>37,找到指针p3。
根据指针p3,找到42、51所在节点,把此节点读入内存,进行第二次磁盘IO,此时发现42<43<51,找到指针p2。
根据指针p2,找到43、46所在节点,把此节点读入内存,进行第三次磁盘IO,此时我们就已经查到了元素43。
在此过程总共进行了三次磁盘IO。
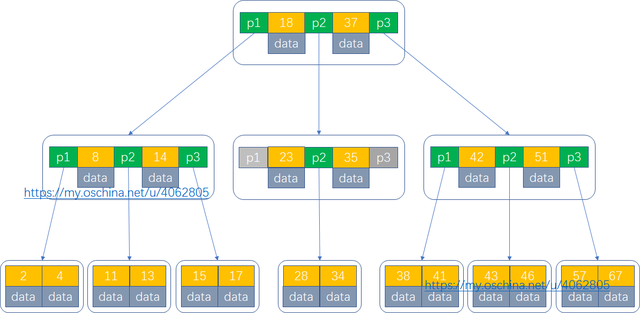
B+Tree
B+Tree属于B-Tree的变种。与B-Tree相比,B+Tree有以下不同点:
有n棵子树的非叶子结点中含有n个关键字(B树是n-1个),即非叶子结点的子树指针与关键字个数相同。这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(B树是每个关键字都保存数据)。所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
所有的非叶子结点可以看成是叶子节点的索引部分。同一个数字会在不同节点中重复出现,根节点的最大元素就是b+树的最大元素。
相对B树,B+树做索引的优势B+树的磁盘IO代价更低: B+树非叶子节点没有指向数据行的指针,所以相同的磁盘容量存储的节点数更多,相应的IO读写次数肯定减少了。B+树的查询效率更加稳定:由于所有数据都存于叶子节点。所有关键字查询的路径长度相同,每一个数据的查询效率相当。
所有的叶子节点形成了一个有序链表,更加便于查找。
关于MySQL的两种常用存储引擎MyISAM和InnoDB的索引均以B+树作为数据结构,二者却有不同(这里只说二者索引的区别)。
MyISAM索引和Innodb索引的区别
MyISAM使用B+树作为索引结构,叶节点叶节点的data域保存的是存储数据的地址,主键索引key值唯一,辅助索引key可以重复,二者在结构上相同。 因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果要找的Key存在,则取出其data域的值,然后以data域的值为地址,去读取相应数据记录 。因此,索引文件和数据文件是分开的,从索引中检索到的是数据的地址,而不是数据。
Innodb也是用B+树作为索引结构,但具体实现方式却与MyISAM截然不同,首先,数据表本身就是按照b+树组织,所以数据文件本身就是主键索引文件。叶节点key值为数据表的主键,data域为完整的数据记录,因此InnoDB表数据文件本身就是主键索引(这也就是MyISAM可以允许没有主键,但是Innodb必须有主键的原因)。第二个与MyISAM索引的不同是InnoDB的辅助索引的data域存储相应数据记录的主键值而不是地址。
换句话说,InnoDB的所有辅助索引都引用主键作为data域。
索引类型
普通索引:(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。
唯一索引: 普通索引允许被索引的数据列包含重复的值,而唯一索引不允许,但是可以为null。所以任务是保证访问速度和避免数据出现重复。
主键索引:在主键字段创建的索引,一张表只有一个主键索引。
组合索引:多列值组成一个索引,专门用于组合搜索。
全文索引:对文本的内容进行分词,进行搜索。(MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引。)
索引的使用策略及优缺点使用索引
主键自动建立唯一索引。经常作为查询条件在WHERE或者ORDER BY 语句中出现的列要建立索引。查询中与其他表关联的字段,外键关系建立索引。
经常用于聚合函数的列要建立索引,如min(),max()等的聚合函数。
不使用索引
经常增删改的列不要建立索引。有大量重复的列不建立索引。表记录太少不要建立索引,因为数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果 。
最左匹配原则
建立联合索引的时候都会默认从最左边开始,所以索引列的顺序很重要,建立索引的时候就应该把最常用的放在左边,使用select的时候也是这样,从最左边的开始,依次匹配右边的。
优点
可以保证数据库表中每一行的数据的唯一性。可以大大加快数据的索引速度。加速表与表之间的连接。
可以显著的减少查询中分组和排序的时间。
缺点
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。索引需要占物理空间,除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间,如果需要建立聚簇索引,那么需要占用的空间会更大,其实建立索引就是以空间换时间。表中的数据进行增、删、改的时候,索引也要动态的维护,这就降低了维护效率。
验证索引是否能够提升查询性能
创建测试表index_test

使用python脚本程序通过pymsql模块,向表中添加十万条数据
import pymysqldef main():# 创建Connection连接conn = pymysql.connect(host='localhost',port=3306, database='db_test', user='root', password='deepin', charset='utf8')# 获得Cursor对象cursor = conn.cursor()# 插入10万次数据for i in range(100000):cursor.execute("insert into index_test values('haha-%d')" % i)# 提交数据conn.commit()if __name__ == "__main__":main()
在mysql终端开启运行时间监测:set profiling=1;

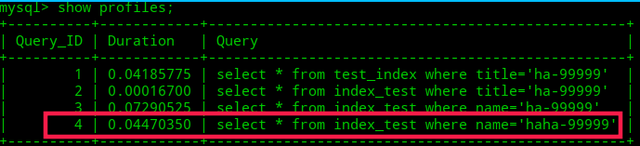
查找第1万条数据ha-99999
select * from index_test where name='haha-99999';
查看执行的时间:
show profiles;
为表index_test的name列创建索引:
create index name_index on index_test(name(10));
再次执行查询语句、查看执行的时间:
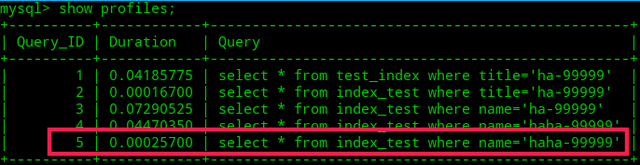
可以看出合适的索引确实可以明显提高某些字段的查询效率。
转自:https://my.oschina.net/u/4062805/blog/3216265
-

- 台湾什么时候回归祖国(浅谈台湾何时回归祖国)
-
2023-06-12 04:05:20
-

- 世上无难事的下一句(要像世上无难事)
-
2023-06-12 04:03:04
-

- 涔拌。鏈嶇殑缃戠珯鍝釜濂?鍝釜APP鏇撮€傚悎涔拌。鏈?
-
2023-06-12 04:00:48
-

- 百元级的“小屏平板”市场:死不了,也做不大
-
2023-06-12 03:58:33
-

- 五月初五端午节的来历和风俗(端午节的来历和风俗是什么)
-
2023-06-12 03:56:17
-

- 被低估的智能门锁,为何成为智能家居顶流?
-
2023-06-12 03:54:01
-

- 乐器大全名称及图片和介绍(中国乐器大全名称及图片)
-
2023-06-12 03:51:45
-
- 形容词的用法有哪些 形容词的用法什么
-
2023-06-11 10:33:26
-

- 英雄联盟s赛历届冠军一览
-
2023-06-11 10:31:11
-
- 不负韶华什么意思 不负韶华是什么意思
-
2023-06-11 10:28:55
-
- 怎么查看自己的手机型号
-
2023-06-11 10:26:39
-
- 火影忍者大蛇丸怎么死的
-
2023-06-11 10:24:24
-
- 北约“空中卫士23”演习将在德国和东欧展开,25国参加
-
2023-06-11 10:22:08
-
- protestor是什么意思_protestor怎么读_中文意思_用法_翻译
-
2023-06-11 10:19:52
-
- 世界上邻国最多的国家排名(世界上哪个国家邻国最多)
-
2023-06-11 10:17:36
-
- 特朗普被明确通知是刑事调查目标,美媒:检方即将提起刑诉
-
2023-06-11 10:15:21
-

- 光遇复刻4.7先祖兑换图一览
-
2023-06-11 10:13:05
-

- 八大原谅是什么梗?
-
2023-06-09 14:43:17
-

- 男生说FB是什么梗?网络用语FB是什么意思?
-
2023-06-09 14:41:01
-

- 丧尸病毒真的存在吗「科普」
-
2023-06-09 15:53:31
 田明建国门案真实原因(由驻京郊某部的一名连长田建明引起)
田明建国门案真实原因(由驻京郊某部的一名连长田建明引起) 甘蔗上绑香蕉是什么意思 甘蔗上绑着香蕉是什么意思
甘蔗上绑香蕉是什么意思 甘蔗上绑着香蕉是什么意思